Deep Learning vs. Hybrid Models in Trading

Deep Learning vs. Hybrid Models in Trading
Deep learning (DL) and hybrid models are two popular approaches in trading. Here’s the key difference: DL models handle everything from data processing to generating trading signals, while hybrid models split tasks - using DL for predictions and classical methods for portfolio allocation.
Key Takeaways:
- DL models excel at identifying complex patterns in raw data but often struggle with volatility and regime shifts.
- Hybrid models combine DL with traditional optimizers (like Sharpe Ratio Maximization), offering better risk control and risk-adjusted returns.
- For example, a standalone Transformer model achieved a 16.34% CAGR (2020–2026), but a hybrid model outperformed it on a risk-adjusted basis.
Quick Overview:
- Performance: Hybrid models often deliver more stable risk-adjusted returns.
- Complexity: DL models are simpler to conceptualize but require large datasets and powerful hardware.
- Best Fit: DL suits high-frequency trading or quantitative research. Hybrid models are ideal for portfolio managers and multi-asset strategies.
Choosing between them depends on your goals, data availability, and trading style. Hybrid models are a better choice for balancing returns and risk management, especially for multi-asset portfolios.
Standalone Deep Learning Models in Trading
Strengths of Deep Learning Models
Standalone deep learning models excel at uncovering nonlinear, complex patterns in raw market data - patterns that traditional rule-based systems often miss. For instance, while a rule like "RSI > 70" gives a simple yes-or-no signal, models like LSTMs or Transformers provide nuanced outputs, such as a probability (e.g., 0.73) that the next price bar will close higher. This added depth can be critical when determining position sizes.
Each type of deep learning architecture has a specific strength:
| Model Type | Primary Trading Application | Key Strength |
|---|---|---|
| LSTM | Sequential price forecasting | Captures long-term dependencies |
| CNN | Local pattern recognition | Identifies localized price movement features |
| Transformer | Global market context | Handles multi-scale and cross-asset dependencies |
While these models offer powerful tools for analyzing market data, their challenges, particularly in live trading, cannot be ignored. These are discussed in the following section.
Limitations of Deep Learning Models
Despite their capabilities, deep learning models face some tough hurdles. A major issue is data scarcity. For example, a single-layer LSTM with 64 hidden units involves over 33,000 trainable parameters. However, three years of daily price data only provides about 750 samples - not nearly enough to train such a model without overfitting. On top of that, approximately 80% of daily price series data is noise, meaning these models often learn patterns that fail to generalize.
This limitation becomes evident in real-world performance. In a 2020–2026 out-of-sample study, a Transformer-based model achieved a Sharpe ratio of 0.83 but suffered a maximum drawdown of -32.66%, nearly double the -16.46% drawdown of a simple equal-weight baseline. As quantitative researcher Jonathan Kinlay explained:
"While the Transformer generates a genuine return signal, it functions primarily as a higher-beta expression of the universe, and struggles to beat a naive equal-weight baseline on a strictly risk-adjusted basis." - Jonathan Kinlay, Quantitative Researcher
Another issue lies in the use of Mean Squared Error (MSE) loss during training. This loss function tends to push predictions toward the average, resulting in forecasts that lack the decisiveness required for meaningful portfolio decisions.
These challenges highlight the importance of integrating these models with complementary systems, which is explored further in the next section.
Integration with MQL5 Trading Systems
To address the challenges of standalone deep learning models, a seamless integration strategy is essential for live trading. A practical workflow involves dividing responsibilities: Python for training, MQL5 for execution. Typically, you train your LSTM or CNN using frameworks like TensorFlow or Keras, export the model in .onnx format, and then embed it into an Expert Advisor (EA) via the #resource directive. Real-time inference is handled by MQL5 functions like OnnxCreateFromBuffer and OnnxRun.
One common pitfall is mismatched normalization parameters. The min/max scaling values used during training in Python must be consistently applied to live market data in MQL5. If not, predictions can silently fail, leading to unreliable outputs. For LSTM models, a typical setup involves a 60-bar lookback window to generate input sequences.
To improve the reliability of raw model outputs, confirmation filters are often used. These include checks like spread thresholds, RSI alignment, and ATR-based volatility gates to filter out low-quality signals. As MQL developer Mauricio Vellasquez explains:
"The AI provides the 'Context,' and the classical code provides the 'Safety.' This combination allows us to capture the adaptability of AI without the chaotic unpredictability of a pure DRL agent." - Mauricio Vellasquez, MQL Developer
For those looking to simplify the process, platforms like Traidies allow you to describe trading logic in plain language, automatically generate MQL5 code, and backtest strategies on historical data - eliminating the need to manually manage the Python-to-MQL5 pipeline.
sbb-itb-3b27815
Deep Learning for ETF Portfolio Allocation: Can it beat SP500?
Hybrid Models for Trading and Portfolio Optimization
Hybrid models combine the strengths of deep learning's pattern recognition with traditional risk management techniques to tackle issues like overfitting, poor risk control, and limited interpretability. Below, we dive into some key architectures and their practical applications.
Examples of Hybrid Model Architectures
Hybrid models often pair a deep learning component with an econometric method, reinforcement learning (RL), or sentiment analysis. Here's a breakdown of how these setups function:
| Hybrid Type | DL Component | Integrated Method | Purpose |
|---|---|---|---|
| ARIMA-LSTM | LSTM | Econometric (ARIMA) | ARIMA identifies linear trends, while LSTM handles nonlinear residuals |
| DQN-Optimizer | Deep Q-Network | Portfolio Optimization (e.g., Sharpe Maximization) | RL picks assets; a classical optimizer allocates capital |
| CNN-LSTM-LLM | CNN-LSTM | LLM Sentiment Analysis | Predicts prices and adjusts weights based on real-time sentiment |
| Wavelet-DL | LSTM / CNN | Wavelet Transform | Filters out high-frequency noise before data enters the model |
For example, in the ARIMA-LSTM framework, ARIMA first models the linear components of the data and passes its residuals to the LSTM, which focuses on capturing nonlinear patterns that ARIMA misses. Meanwhile, the DQN-Optimizer setup separates decision-making: the RL agent determines buy, sell, or hold actions, while a traditional optimizer, like Sharpe Ratio Maximization, manages capital allocation. This division simplifies the action space and prevents concentrated portfolios, a common issue with standalone RL models.
These hybrid systems showcase how combining deep learning with traditional methods can enhance both signal extraction and portfolio management.
Benefits of Hybrid Models
Hybrid approaches have demonstrated strong performance improvements in practice. A notable example comes from Bahir Dar University researchers Arega Denekew, Tesfahun Berehane, and Molalign Adam. In October 2025, they introduced a CNN-LSTM model enhanced with LLM-based sentiment analysis. Tested on ETFs such as VTI, AGG, DBC, and VXX, their system achieved a Sharpe ratio of 1.623, outperforming traditional Mean-Variance Optimization (MVO) and Conditional Value-at-Risk (CVaR) methods by 104% to 300%. The addition of the sentiment layer alone boosted the Sharpe ratio by 28.18%.
"The incorporation of LLM sentiment signals improves the Sharpe ratio by 28.18%, and sensitivity tests guarantee robustness across regimes." - Arega Denekew, Researcher, Bahir Dar University
Another example comes from Concordia University researchers Soroush Shahsafi and Farnoosh Naderkhani. In February 2026, they tested a DQN-based hybrid on emerging-market ETFs and U.S. equities. By using DQN for asset selection and Sharpe Ratio Maximization for allocation, they achieved consistent outperformance compared to other allocation strategies.
"This combination lets the agent select assets while the optimizer produces risk-aware allocations." - Shahsafi & Naderkhani, Concordia University
Splitting asset selection and capital allocation in this way enhances risk management, making portfolios more stable.
Challenges of Hybrid Models
Despite their advantages, hybrid models come with their own set of challenges. They are more complex to design and maintain than standalone models, as each component adds layers of hyperparameters, data demands, and potential points of failure. For instance, in an ARIMA-LSTM pipeline, any drift in the ARIMA model can silently degrade the overall system's performance.
Another risk is overfitting to historical quirks. To mitigate this, techniques like Walk-Forward Optimization (WFO) during hyperparameter tuning can help ensure the model performs well across varying market conditions. Additionally, hybrid models often require significant computational resources. This is especially true for DQN-based hybrids, where training in a multi-asset environment with continuous rebalancing can be hardware-intensive.
Deep Learning vs. Hybrid Models: A Direct Comparison
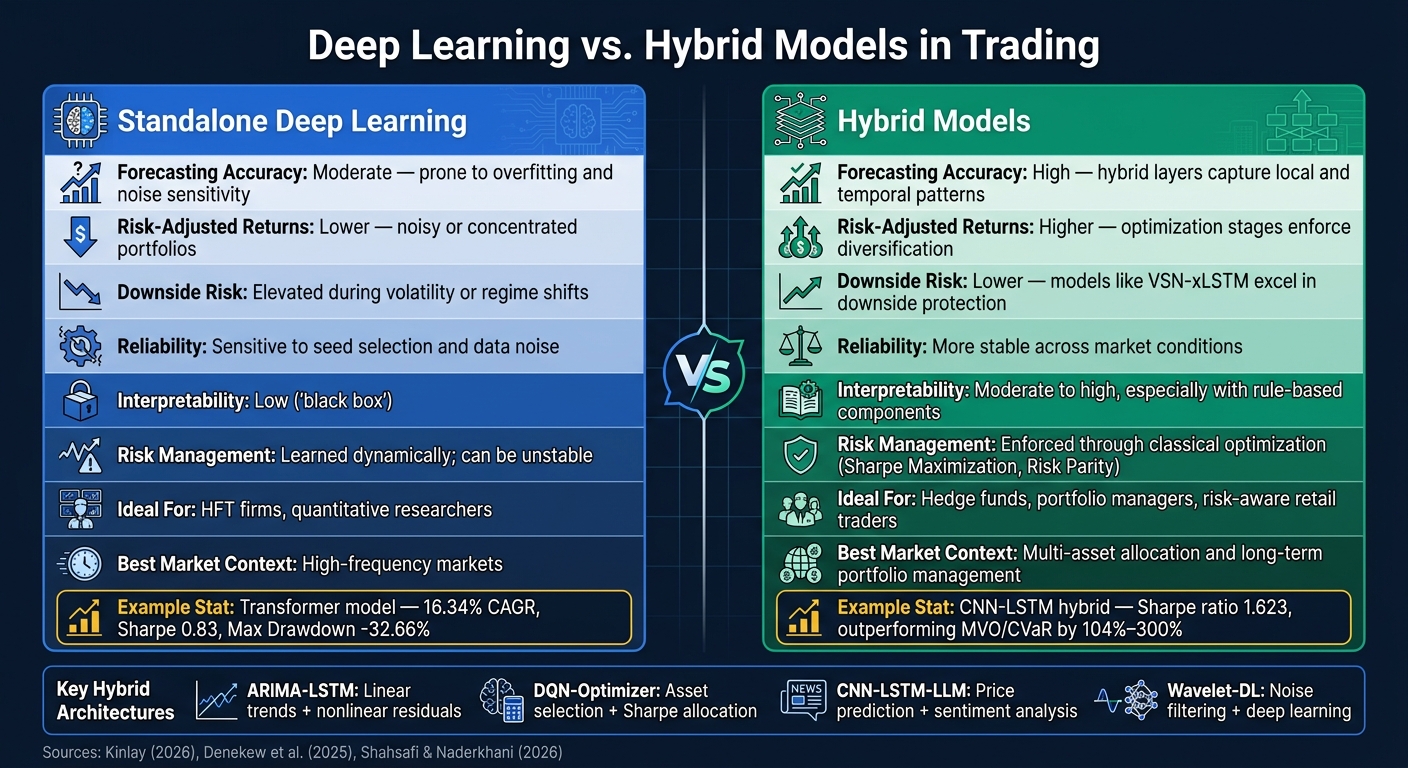
Deep Learning vs. Hybrid Models in Trading: Side-by-Side Comparison
Let’s break down how these two approaches stack up in terms of performance, complexity, and suitability for different traders.
Performance and Risk Metrics
Hybrid models often outperform standalone deep learning when it comes to risk-adjusted returns. Why? It’s all about structure. Standalone models, like LSTMs, try to handle everything - signal extraction and capital allocation - in one go. This can lead to portfolios that are either too noisy or overly concentrated. Hybrid models, on the other hand, separate these tasks, allowing for more precise optimization.
For example, architectures like CNN-LSTM hybrids show lower Root Mean Square Error (RMSE) and Mean Absolute Error (MAE) compared to standalone LSTMs or CNNs across diverse datasets. Variable Selection Networks (VSN) paired with LSTMs also deliver the highest Sharpe ratios in benchmarks spanning 2010–2025. Researchers Soroush Shahsafi and Farnoosh Naderkhani from Concordia University found that combining classical optimization with Deep Q-Networks (DQN) improves return-risk metrics, reinforcing the edge hybrid models have over standalone systems.
Standalone models are also more vulnerable to random seed selection and data noise, making consistent replication a challenge. In contrast, hybrid models - especially those incorporating meta-learners like XGBoost to refine signals - tend to be more reliable across different market environments.
| Metric | Standalone Deep Learning | Hybrid Models |
|---|---|---|
| Forecasting Accuracy | Moderate; prone to overfitting and noise sensitivity | High; hybrid layers capture both local and temporal patterns |
| Risk-Adjusted Returns | Lower; often produces noisy or concentrated portfolios | Higher; optimization stages enforce diversification |
| Downside Risk | Elevated during volatility or regime shifts | Lower; models like VSN-xLSTM excel in downside protection |
| Reliability | Sensitive to seed selection and data noise | More stable across market conditions |
This performance gap leads to differences in implementation complexity, which plays a big role in determining suitability.
Implementation Complexity and Data Requirements
Standalone deep learning models are simpler in concept but extremely data-hungry. They require vast, high-quality datasets to avoid overfitting, and adding layers (like LSTMs) demands significant memory and processing power. Their "black box" nature also makes it tough to explain their decisions - something that can be a headache for compliance or risk teams.
Hybrid models, while more complex in setup, offer a different set of challenges. Developers need to carefully align the various components, manage computational costs, and ensure compatibility between architectures. However, their modular design allows for task separation - like using DQNs for asset selection and classical optimizers for portfolio weighting - which simplifies the overall action space compared to end-to-end reinforcement learning. Hybrid models also shine when handling diverse data sources, seamlessly integrating price history, macroeconomic indicators, and sentiment signals - areas where standalone models often struggle.
These differences in complexity and data needs influence which traders are best suited to each approach.
Which Trader Profiles Fit Each Approach?
Choosing the right approach boils down to your resources, goals, and risk appetite. Standalone deep learning is a good fit for quantitative researchers and high-frequency trading (HFT) firms. These traders typically have access to massive datasets, powerful GPU infrastructure, and teams comfortable working with opaque, "black box" models. Standalone systems excel in high-frequency markets where the ability to recognize patterns quickly is a key advantage.
On the flip side, hybrid models are better suited for portfolio managers, hedge funds, and risk-conscious retail traders. Their modular design makes them easier to integrate with existing risk management systems, and the inclusion of classical optimization provides greater transparency compared to pure deep learning.
| Dimension | Standalone Deep Learning | Hybrid Models |
|---|---|---|
| Ideal For | HFT firms, quantitative researchers | Hedge funds, portfolio managers, risk-aware retail traders |
| Interpretability | Low ("black box") | Moderate to high, especially with rule-based components |
| Risk Management | Learned dynamically; can be unstable | Enforced through classical optimization (e.g., Sharpe Maximization, Risk Parity) |
| Best Market Context | High-frequency markets | Multi-asset allocation and long-term portfolio management |
How to Choose Between Deep Learning and Hybrid Models
The previous section outlined which trading profiles align with each approach. Now, let’s dig deeper into how to choose the best method based on your data availability and execution complexity. Here’s how you can determine which approach fits your trading strategy:
When Standalone Deep Learning Makes Sense
Standalone deep learning thrives under specific conditions, and data volume is the key factor. Without enough data, models risk overfitting - essentially memorizing noise instead of identifying meaningful patterns.
This approach is ideal when you’re working with tick-level or L2 order book data that exceeds 100,000 samples, or if you’re handling unstructured data like earnings call transcripts for NLP-based alpha generation. However, if simpler models like regularized linear regressions fail to predict market direction effectively, adding neural network layers won’t magically improve accuracy.
"Deep learning gets picked because it looks impressive, not because it works better on financial data." - D&T Systems
When Hybrid Models Are the Better Choice
For retail traders or portfolio managers dealing with daily or hourly bars across multiple assets, hybrid models are often the smarter option. Financial time series are notoriously noisy - up to 80% of the data is essentially noise. Hybrid models tackle this by breaking down the problem into two stages: signal extraction and capital allocation. Tools like Mean-Variance Optimization (MVO) or Sharpe Ratio Maximization are used to fine-tune portfolio weighting.
This separation is especially important for multi-asset portfolios, where managing cross-asset relationships and systemic risks becomes crucial. Hybrid models also have a practical advantage - they can retrain in seconds or minutes using standard CPU hardware, unlike standalone deep learning, which often requires GPU resources and hours of processing.
As Adir Saly-Kaufmann from the Machine Learning Research Group at the University of Oxford explains:
"Effective financial forecasting models benefit from jointly denoising returns, learning asset-specific and regime-aware dynamics, and encoding temporal structure in a stable and adaptive manner."
After understanding the strengths of each method, the next challenge is implementing them efficiently.
Using Traidies to Automate Strategy Implementation

Given the complexity of building these models, automation can simplify the process. Manually creating a hybrid pipeline in MQL5 - writing OpenCL kernels for attention mechanisms, managing global data buffers, and converting ONNX models from Python - can be a time-consuming and fragmented workflow. Typically, you’d need to export data, train in TensorFlow or Keras, convert to ONNX, and then embed it into MQL5.
Traidies eliminates much of this hassle. It allows you to describe your strategy in plain language - whether it’s a standalone LSTM signal or a hybrid DQN-plus-optimizer setup - and then generates the required MQL5 code automatically. This lets you run automated backtests on historical data without piecing together a cross-platform pipeline. It’s particularly useful for testing whether your hybrid architecture improves risk-adjusted returns before committing to a full deployment. By reducing technical overhead, Traidies lets you focus on the most important part: validating your strategy logic.
Conclusion
Deciding between standalone deep learning and hybrid models isn't about chasing complexity - it's about finding the right fit for your trading needs.
Standalone deep learning shines when handling nonlinear patterns in high-frequency, unstructured data. However, it comes with a higher risk profile: it often boosts returns during market rallies but can falter during drawdowns or regime changes. Hybrid models tackle these challenges by splitting the responsibilities - using deep learning for signal generation and a classical optimizer for position sizing. This separation enhances risk management while maintaining strong signal quality. Across the comparisons discussed here, this structural approach has consistently delivered better risk-adjusted performance.
Key Takeaways
Here are a few guiding principles to keep in mind when choosing your approach:
- Keep it simple at first. Start with regularized linear models or XGBoost before introducing neural network layers. Only increase complexity if simpler models stop improving.
- Divide tasks for better results. Use deep learning for generating trade signals and pair it with a classical optimizer for position sizing. This separation improves both clarity and downside protection.
- Validate thoroughly. Always implement walk-forward cross-validation with at least five folds to ensure your model performs well outside the training window.
Once you've chosen your approach, the next step is execution. Platforms like Traidies make this process easier by automating strategy implementation. Whether you're testing a standalone LSTM signal or creating a hybrid model, Traidies lets you describe your strategy in plain language and generates MQL5 code for you. This way, you can focus on refining your strategy without worrying about infrastructure.
FAQs
What’s the simplest hybrid model setup I can start with?
A simple hybrid model blends the strengths of traditional statistical or machine learning approaches with deep learning techniques. Here's how it works: you begin with a foundational model - such as ARIMA or LSTM - to generate initial predictions. Then, you enhance these predictions by introducing a sentiment analysis layer, like VADER or FinBERT.
This combination allows you to merge quantitative signals (from the initial model) with qualitative sentiment data, creating a more nuanced and effective system. It's particularly useful when working with limited datasets and offers flexibility to grow and improve as you gain more experience.
How much data is needed for deep learning to be effective in trading?
Deep learning in trading thrives on large, high-quality datasets, often covering years of historical data. These extensive datasets allow models to identify complex patterns while minimizing the risk of overfitting. However, financial data presents unique challenges - it’s often noisy and non-stationary, meaning it can fluctuate unpredictably over time. To achieve reliable outcomes, ensuring both the quality and quantity of the data is absolutely essential.
How can I reduce drawdowns when a deep learning signal breaks in a new regime?
To navigate drawdowns during regime shifts, hybrid models can be a game-changer. These models blend deep learning with either traditional techniques or machine learning methods, creating a more adaptable approach. For instance, pairing LSTM with sentiment analysis or using Transformer-MVO pipelines can enhance stability by integrating different methodologies.
Another effective strategy involves reinforcement learning frameworks combined with portfolio optimization. These frameworks dynamically adjust positions, helping to manage risks and sustain performance even when signals start to falter.